Why (not) Neo4j?
The database engine of choise for Hyperion was decided as Neo4j, that said it was not the only (nor arguably not the best) engine available. The main reasoning behind choosing Neo4j was ROI and the ease of creating an initial MVP. That said, unfortunately Neo4j lacks of lot of nice-to-have features which make it more challenging to efficient manage a graph database of this scale and breadth. Specifically Neo4j:
- Does not allow proper schema enforcement - you can create constraints, but that does not prevent someone from creating new arbitrary/wrongly named properties and node labels.
- Does not allow regex-based constraints - for predictable values like IPv4, Emails, hashes etc. it is best to have constraints on the value of these entities. Sadly, Neo4j only allows to limit the field type to a
string, you cannot make further adjustments. This leads to junk data potentially being loaded into the DB and requires post-write validation to delete offending nodes. - User-defined functions - Neo4j does not easily allow to write user defined functions like Vertex Synapse where you can execute a query like
passivetotal.pdns.enrichwhich fetches pDNS enrichment from RiskIQ. Instead, you need to make anapoc.load.json(URL)call to an enrichment API, which is cumbersome.
Consequently, it is possible that in the future Hyperion will migrate its database to a more fiting database engine, of which there are 2 primary candidates: SurrealDB and TypeDB.
Viable alternatives
SurrealDB
SurrealDB is a multi-model database built on top of a document database powered by RocksDB (for single node) or FoundationDB (for distributed storage). As a document database it is very flexible, allowing to operate both in schemaless and schemafull configurations, configured per-table.
Other useful features of SurrealDB include:
- Pluggable storage system (RocksDB, FoundationDB, TiKV or fully in-memory)
- Event triggers
- Very good variety of pre-made functions for temporal, geospatial, string, HTTP and other operations types, wih support for further user-defined functions
- Computed parameters (i.e. calculated at query time)
- OAuth SSO
It uses an SQL-like query language with the added support for graph traversals using the RELATE statement for edge definition and a -> operator for edge traversal, for example:
-- Creating a relationship
RELATE person:Bartosz->wrote->"article:Why (not) Neo4j?";
-- Traversing a relationship:
SELECT ->wrote->article FROM person:Bartosz
-- But it can also be written as
person:Bartosz->wrote->article SELECT
SurrealDB also supports embedding Record link allowing to embed nodes within one another, which can be useful for meta-nodes such as DNS records, which need to store the IPv4 and FQDN related to the DNS record.
-- Embed the "Bartosz" person node ID within the article node
CREATE "article:Why (not) Neo4j?" SET author = [person:Bartosz]
-- Retrieve all articles written by Bartosz
SELECT * FROM article WHERE author = [person:Bartosz ]
-- You can also retrieve a property from the embedded record
SELECT author.name FROM article WHERE author = [person:Bartosz]
Unfortunately, this functionality is not exactly what you'd expect, as trying to go the other way around - i.e. pivot from the person node to the article is seemingly not possible, as the database will not actually create a record for the person if it does not exist, neither will it store any link in the person node.
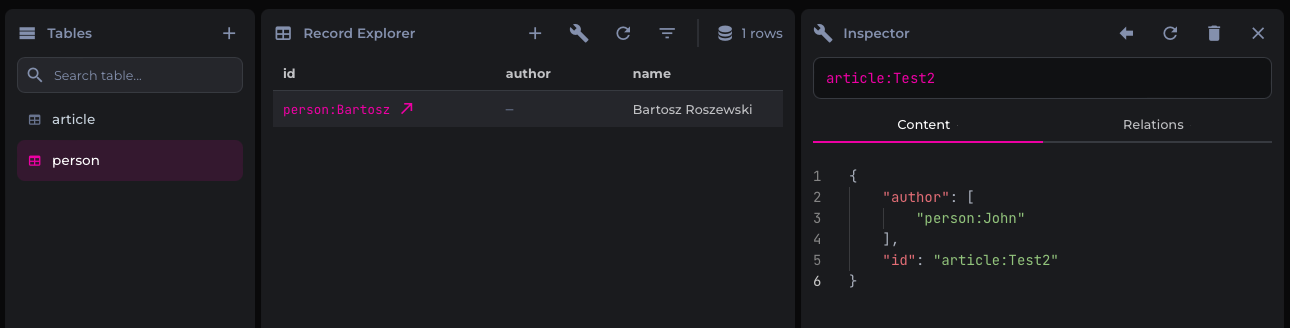
Notice how despite the article:Test2 node embedding the person:John node as its author, the person:John node does not get created in the person table. That said, it's still useful as it can be used in addition to the regular relationships created with RELATE, as you can create both the relationship and embed the node link, for example:
-- Create the DNS record embedding the IP and FQDN
CREATE dns_a:TestDNS SET ipv4 = [ipv4:`1.1.1.1`], fqdn = [fqdn:`google.com`]
-- RELATE the DNS record to the IP and FQDN for pivoting
RELATE dns_a:TestDNS->related_to->fqdn:google.com
RELATE dns_a:TestDNS->related_to->ipv4:1.1.1.1
-- This then allows queries like for simple and quick lookups:
SELECT * FROM dns_a WHERE dns_a.ipv4.asn=1337
-- Or even embedding multiple layers:
SELECT * FROM dns_a WHERE dns_a.fqdn.whois.registrar CONTAINS "Namecheap"
-- But at the same time you can do pivots for more advanced analytics.
-- Example: For the given DNS record, pivot to the FQDNs and return all other associated DNS records
SELECT ->related_to->fqdn<-related_to<-dns_a FROM dns_a:TestDNS
MongoDB
MongoDB is one of the most well known noSQL databases. While it's a document database that has no native support for graph use cases, MongoDB does support many other features needed by Hyperion:
- Schema validation
- Geospatial & Temporal data types and functions
- Node links (i.e. linking to records in other tables, similar to Foreign Keys in SQL)
- Massively scallable
- Supported by many data science tools out of the box
Because of its scalability, Mongo can be adapted to be used as a "graph-like" database, where either:
- Records contain references to other records, and SQL-style JOINs are used to pivot between data types
- Records contain an array of "relationships" between nodes (this is how SurrealDB implements graphs, it just provides a convinent abstraction layer for this functionality in the form of the
RELATEcommand and the->operator)
For example, a record would have a list of _rels_to references which are the outbound relationshipsp from the node, as well as _rels_to containing a list of incoming relationships:
// Example of a node
{
"_id": "65e5c8ada602da3ea17796ec",
"name": "Bartosz Roszewski",
"role": "CTI Engineer",
"_rels_from": [
"063403be-26d9-42ae-836b-21264d29aad5"
],
"_rels_to": [
"42227470-83d4-4a16-8f04-a26f1887002c"
]
}
//Example of a relationship:
{
"_id": "42227470-83d4-4a16-8f04-a26f1887002c",
"name": "Person_Has_Name"
}
TypeDB
TypeDB is a nieche database originally designed for use cases like CTI, and follows a roughly similar mindset to Vertex Synapse, being strongly typed it would be an interesting alternative to Neo4j, however 2 major issues have been identified:
- According to its Github repo, TypeDB is currently being rewritten to Rust, which brings a big change to its database engine being moved from RocksDB to a custom-written byte store. Consequently, it is difficult to accurately assess TypeDB as the Rust version of it might bring wildly different performance and licensing.
- The TypeDB query language is extremely simplistic, instead relying on most logic to be performed application side. While this is fine for small datasets, when running queries on 100,000+ of rows, returning all that data to the application for computation is extremely inefficient.
Rejected alternatives
The databases listed below were also looked at, however they were rejected for not meeting required criteria.
PostgreSQL + AGE library
Rejection reason: Lack of temporal/geospatial support, data is formatted as custom JSON columns instead of actual SQL types, limited Cypher functionality.
The AGE extension to PostgreSQL allows treating the normally relational database as a graph and makes it behave like a schema-less platform.
--- You can execute Cypher queries like so:
SELECT *
FROM cypher('hyperion_graph', $$
MERGE (a:Person {name: "John Doe"})
SET a.dob="1990-01-01", a.deceased=False, a.bio="Greatest hacker alive"
RETURN a
$$) AS (a agtype);
While AGE certain benefits from the massive scallability of PostgreSQL, it is not really intended to be used as an addition to an existing dataset, but rather as a feature to be used on purpose-built databases. This is caused by the fdact that the feature set of the AGE extension is very limited, including:
- Cypher support only covers basic queries and data-types, for example: no support for temporal or geospatial properties, no access to APOC functions, no path finding etc. This unfortunately removes a lot of the benefits of a true "graph" database.
- Cannot enforce any schema constraints - while PostgreSQL by definition is schemafull, because the properties of nodes are stored as JSON blobs, they cannot be enforced with the same granularity.
- The JSON data is actually not formatted in a "normal" SQL fashion - all properties are stored as
agtypewhich cannot be queries with regular SQL syntax, so a query like this will not work.
SELECT properties->'name' AS person_name FROM hyperion_graph._ag_label_vertex
ArangoDB
Rejection reason: requires paid license, nothing groundbreaking compared to OSS sollutions like SurrealDB.
ArangoDB is a multi-model database supporting key-value, document and graph data models (technically, its just a document database with abstractions for graph modelling and key-value operations).
Memgraph
Rejection reason: cannot scale due to in-memory design
Memgraph is a direct competitor/alternative to Neo4j, using the same query language (Cypher) and data model. It's main use case is the different primary use case - Memgraph's DB is meant to be stored in-memory for real-time analytics, making storing very large graphs inefficient. It also does not support clustering, which is ewentually going to be needed for Hyperion.
Vertex Synapse
Rejection reason: insane cost, scaling almost certainly limited (single-node by design, written in Python, inefficient storage engine)
Vertex Synapse started the whole Hyperion project as it was used by the CTI Team for over a year for CTI research, however due to prohibitive cost and scalling concerns it was decomissioned in favour of Hyperion.