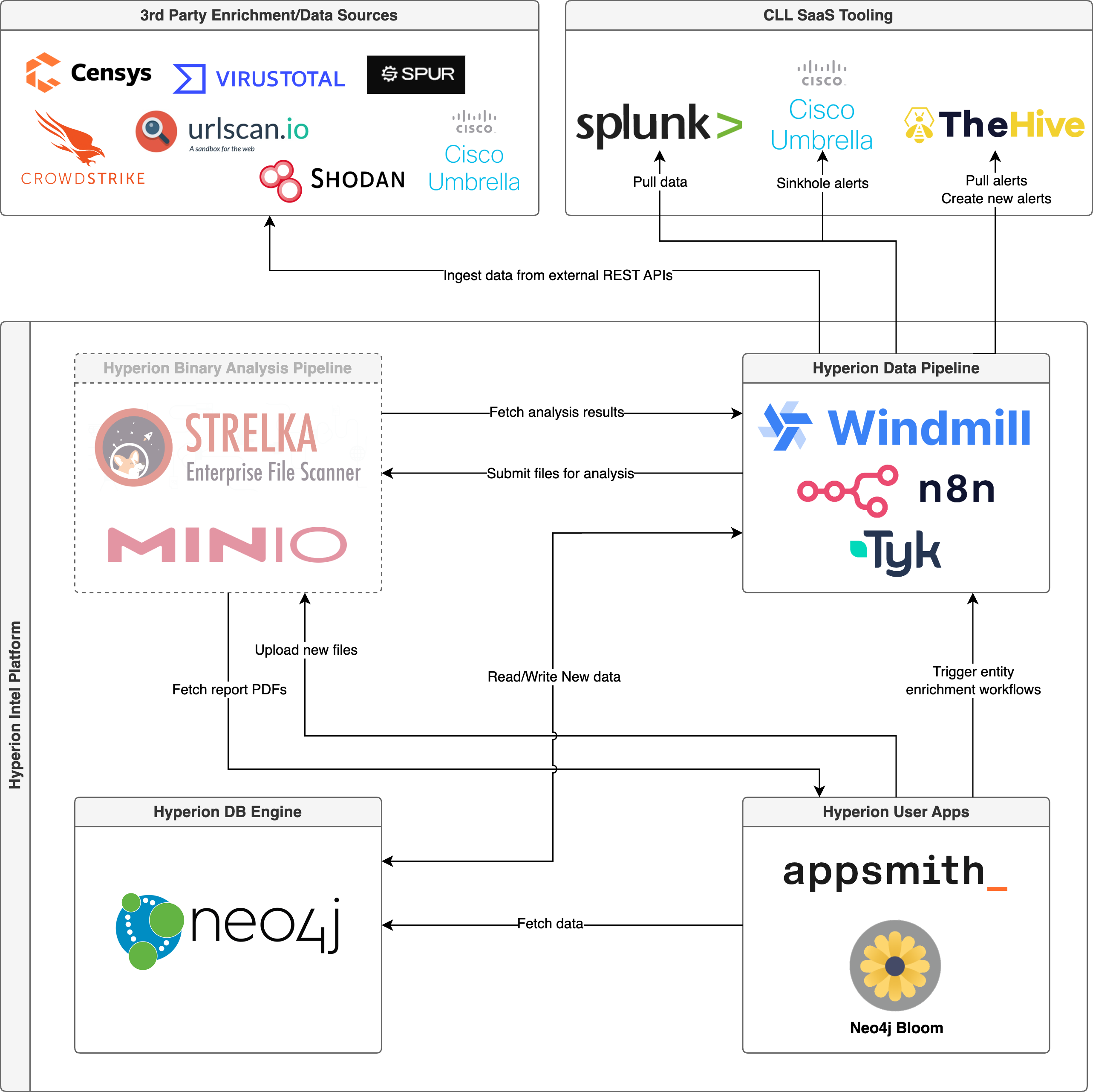
Hyperion Architecture
Hyperion consits of 4 major components:
-
Hyperion DB Engine - responsible for storing entities and their relationships. Based solely on Neo4j.
-
Hyperion Data Pipeline - responsible for loading data into the database, entity enrichment and alerting. The Data Pipeline is made up of 3 sub-components:
-
Windmill - handles high-throughput/low-latency analytics and enrichment.
-
n8n.io - a quick & dirty automation tool for prototyping and less resources intensive workloads
-
Tyk API Gateway - abstracts the API as a single
api.oobtel.networkservice, so a user can query enrichment without needing to know if they're actually using Windmill or n8n.io
-
-
Hyperion User Apps - responsible for all user-facing interactions, and currently comes in 2 variants:
-
Neo4j Bloom - used for graph exploration and general purpose analytics
-
Appsmith - a low-code UI builder used for more specific workflows
-
-
Hyperion Binary Analysis Pipeline - currently not implemented, the Binary Analysis Pipeline will be used for high-volume static analysis of ingested files. Planned to be implemented with:
- Strelka (https://target.github.io/strelka/) - for the actual scanning/parsing
- mquery (https://cert-polska.github.io/mquery/) - for retrohunting on binaries using YARA rules
- Minio - for storing the binaries in an S3-compliant data store.
High level architecture diagram
Please refer to the detailed service diagrams for Hyperion Data Pipeline or the Binary Pipeline for more details.