Hyperion Binary Pipeline Introduction
The Hyperion File Analysis Pipeline consists of the following components:
- Strelka - a static analysis framework developed by Target, with pre-built scanners for multiple file types including MachO, PDF, ELF, PE etc. This is the primary workhorse of this subsystem and is responsible for analysis of all incoming binaries.
- mquery - a YARA scanning tool developed to facilitate scanning thousands of binaries at the same time. mquery will be used for retrohunting newly developed YARA rules against previously analysed and stored binaries.
- Minio - S3-compatible object storage, used for storing the binaries and the mquery index
Architecture diagram
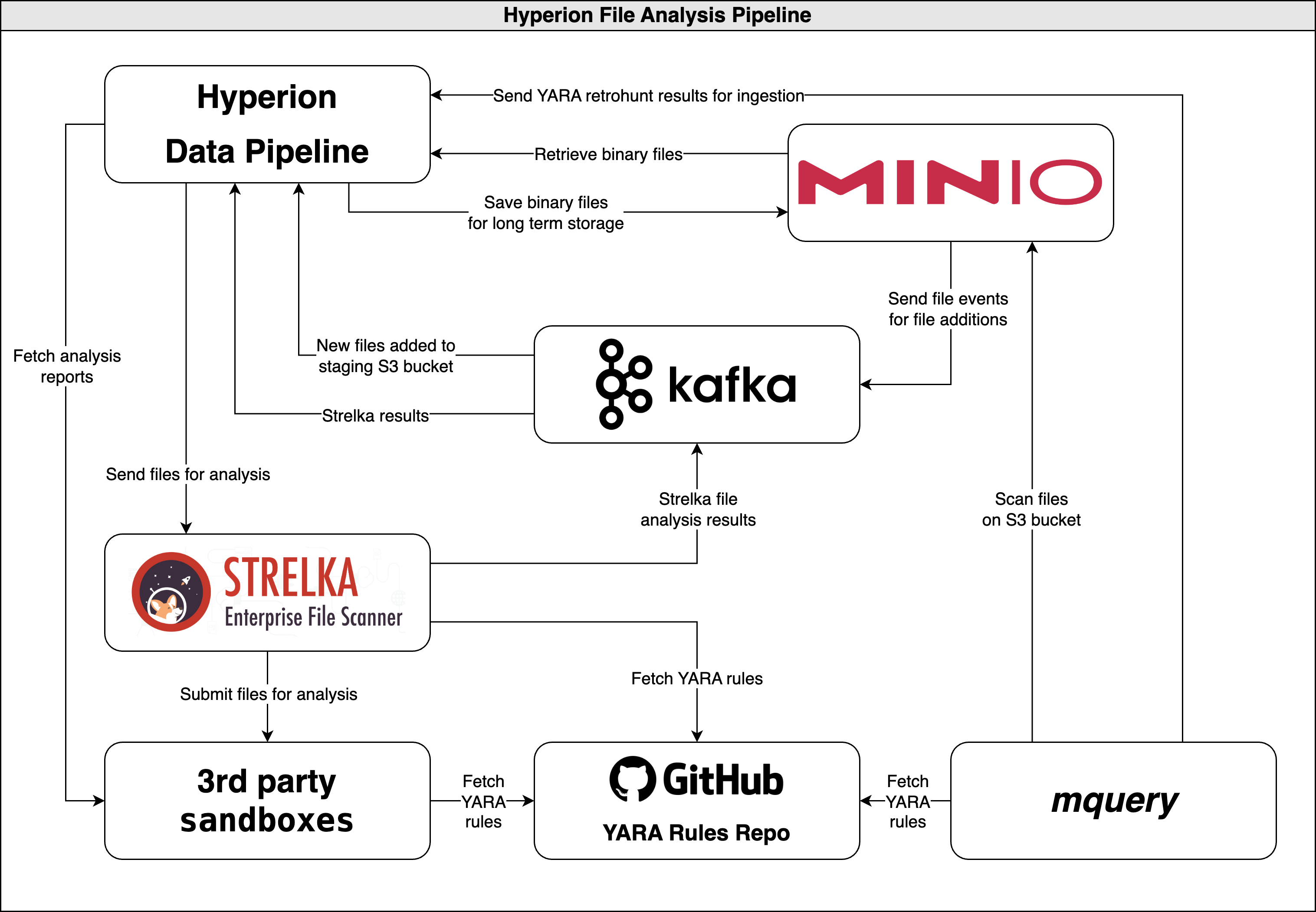
High level workflow overview
Scenario 1: new file sent to analysis directly from the Data Pipeline
- New binaries get sent by the Hyperion Data Pipeline to Strelka for analysis
- At the same time, the binary gets moved into Minio for long-term storage (Strelka does not retain the binary after analysis)
- If requested, Strelka also forwards the binary to external analysis for behavioural analysis
- Strelka sends back analysis results to the Data Pipeline via Kafka, the Data Pipeline saves results into HyperionDB
- If the file was submitted to an external sandbox, the Data Pipeline will ingest the analysis results once scanning is complete (this process is asynchronous since there can is a large delay between the time static and dynamic analysis is finished).
Scenario 2: new file sent to analysis by manual upload
- An analyst uploads a file to be scanned to the "staging" S3 bucket
- Minio sends a file PUT event via Kafka to the Data Pipeline, which then kicks off the same workflow as the one mentioned in Scenario 1.
Scenario 3: new YARA rule used to retrohunt on stored binaries
- When a new YARA rule is developed by an analyst, mquery is used to search through the binary datastore in Minio
- The Data Pipeline periodically ingests mquery "jobs" (i.e. retrohunts) into HyperionDB